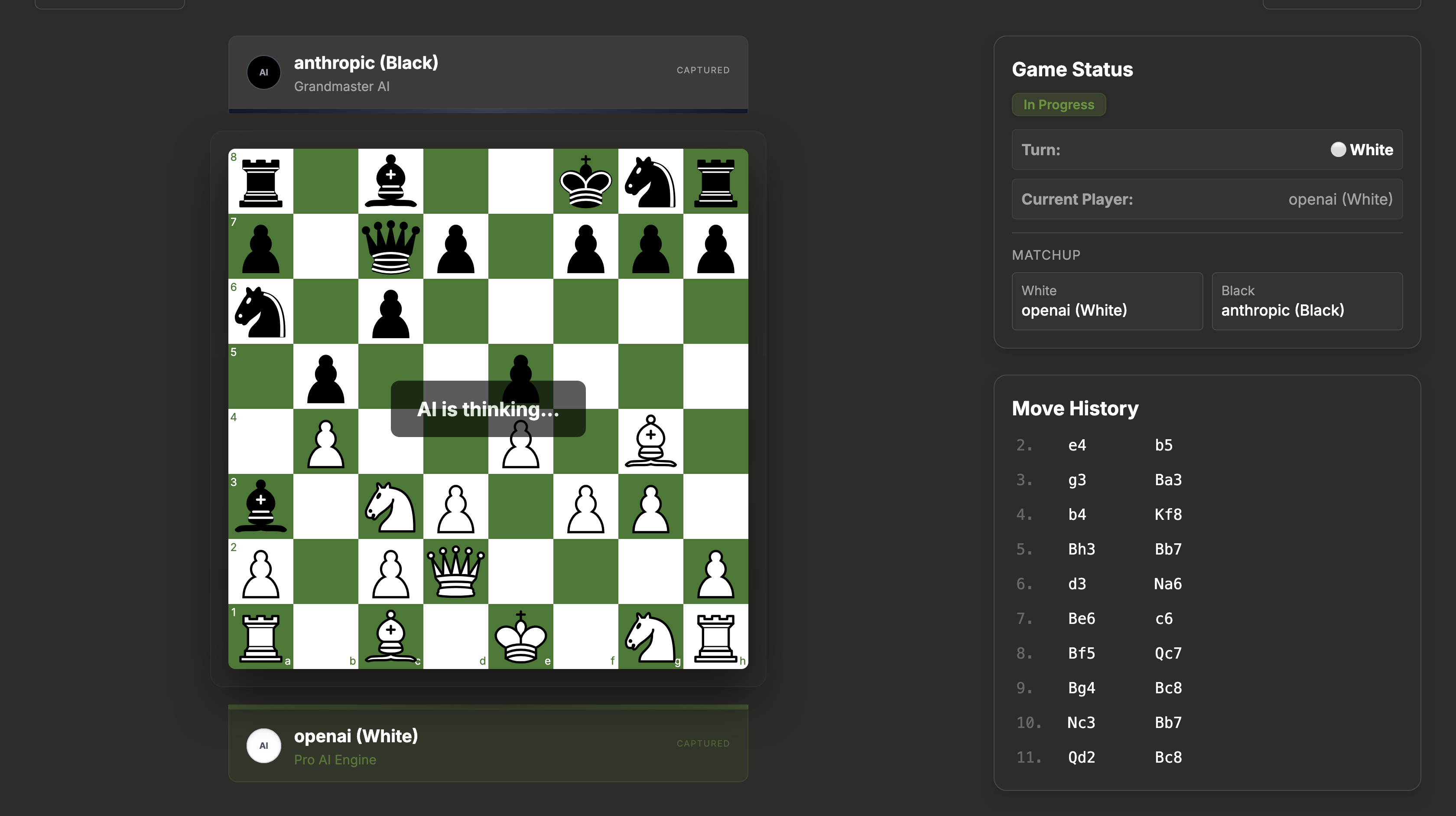
I built ChessLM, an open-source platform to benchmark LLMs against each other (and you) in real chess matches. This wasn't just to ship a product, but to level up my own skills.
I wired up GPT-4o, Claude 3.5 Sonnet, Gemini Pro 1.5, and Grok-2 to a live chessboard and let them play. What I didn't expect was how differently each model approaches the game. Same board. Same rules. Completely different personalities.
The Model Personalities
- Claude 3.5 Sonnet: Plays like it's thinking three layers deep.
- GPT-4o: Aggressive and proactive.
- Grok-2: Bold and takes calculated risks.
- Gemini Pro 1.5: More cautious, sometimes hesitates in complex positions.
I wasn't just benchmarking them; the data started telling its own story.
The Results: Estimated Elo & Win Rates
| Model | Estimated Elo | Win Rate |
|---|---|---|
| Claude 3.5 Sonnet | 2900 | 72% |
| GPT-4o | 2850 | 68% |
| Grok-2 | 2820 | 66% |
| Gemini Pro 1.5 | 2780 | 64% |
Every game played generates real data on how different neural architectures approach tactical planning, strategic depth, and long-horizon reasoning. Whether you're a grandmaster or a beginner, your match contributes to that dataset.
Watch the Action
Join the Open Source Journey
🚀 Open Work #1
- 🔗 Live: chesslm.ovishekh.com
- ⭐ GitHub: github.com/ovishkh/ChessLM
Drop a star if you find this useful. PRs are always welcome!